

This is part of an ongoing series making QuantJourney's architecture visible. This post explains the architecture through the workflows a portfolio manager uses day to day - and shows what each one forces underneath.
A PM does not experience a platform as services, repositories or deployment units. They experience it as workflows: import a portfolio, understand exposure, explain a P&L move, compare current holdings to a target book, run a rebalance, defend a decision six months later.
That is the surface. Underneath every one of those workflows sits the same question, and it is the only architectural question that matters:
What has to be owned underneath for this workflow to stay reliable, reproducible, and safe to automate?
Systems that answer this well cost hundreds of thousands of dollars to build, because the complexity is tremendous - it shapes the architecture and forces rigid, disciplined execution all the way down.
We chose a microservices architecture: a modular buy-side platform built from domain services, data products, platform services, UI apps, SDKs and MCP/AI access layers. But the modularity is not the point.
Let me start by walking through four real PM workflows:
Four workflows that decide the architecture
1. Portfolio import → identity → state → risk → reconciliation.
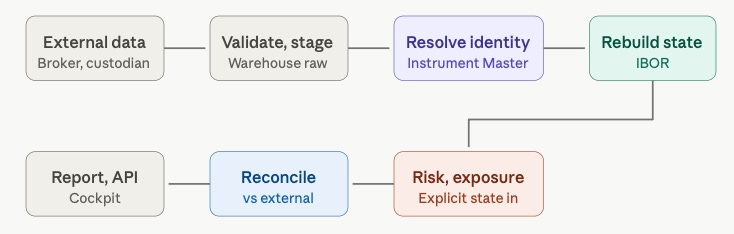
No fund starts with clean state. It starts with broker exports, custodian files, cash movements, fees, corporate actions, stale prices and corrections. That single workflow forces four boundaries. Identity cannot be owned by every importer - if each one decides what BRK.B, an ADR or a stale ticker means, you end up with several incompatible versions of instrument truth, so Instrument Master is its own domain. State is not a holdings table - real investment state is trades, cash, income, FX, tax lots, valuation policy and settlement status, so IBOR is its own domain. Risk cannot run on whichever extract is convenient; it runs against an explicit portfolio state with a known time basis. And reconciliation against external records is an operational workflow, not a UI warning.
2. Current portfolio → target book → optimizer → rebalance → trade intent.
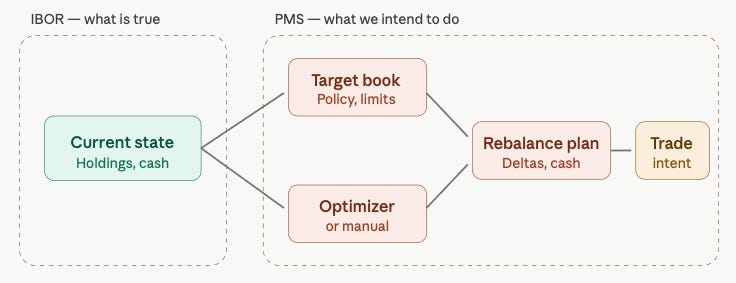
A PM manages what the book should become, not only what it is. This forces the single most important boundary on the buy side: current state ≠ intent. A holding is fact. A target is intent. A rebalance plan is a proposal. A trade intent is not an execution; an execution is not settlement; settlement is not reconciliation. Collapse those into one positions table and “position” silently means six different things depending on which screen produced it. Fine in a spreadsheet. Fatal in a platform you intend to automate with AI. So IBOR and PMS stay separate domains that talk through contracts.
3. Research thesis → monitored signal → alert → decision → attribution.
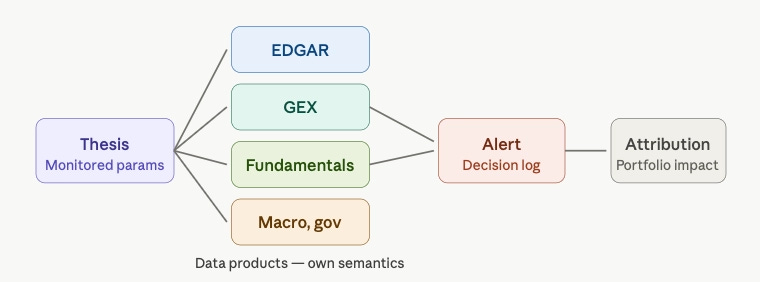
A thesis is only valuable when it can be monitored, linked to data, tied to a decision, and reviewed after the fact. And theses lean on datasets that are not interchangeable: EDGAR filings, options-derived GEX, Sharadar fundamentals, 13F flows, congressional disclosures, macro series, etc. Each has different semantics, freshness, revision behaviour and failure modes. So we treat the serious ones as data products that own their meaning, not connectors dumping rows into one warehouse where the semantics go to die. QuantJourney runs more than seventy of these connectors today, each feeding a Bronze/Silver/Gold pipeline rather than a single undifferentiated bucket.
4. A number on a screen → “where did this come from?”
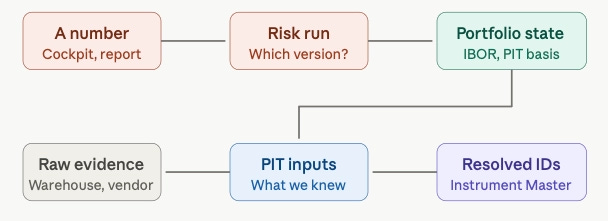
This is the workflow every other one eventually collapses into. A PM looks at an exposure, a risk figure, a P&L attribution, and asks the only question that matters under scrutiny: can you explain it? Answering means drilling backward - through the risk run that produced it, the portfolio state and time basis it used, the resolved instruments behind the positions, down to the raw vendor evidence underneath. That drill-down is only possible if every layer has a known owner, a versioned contract and point-in-time semantics. In a tangled system the honest answer is “we think so, give us a day.” In a platform built on ownership boundaries, the answer is a click. This workflow is the reason all the others have to be clean.
Notice what happened: I never argued for microservices. The workflows did. Identity, warehouse, IBOR, PMS, risk, reconciliation, data products, PIT, governed access, infra - each exists because a workflow above it would otherwise produce a number nobody can trust.
In QuantJourney, those boundaries map into concrete modules:
Instrument Master - canonical assets, identifiers, listings, ticker history, corporate actions
Warehouse - raw evidence, PIT facts, materialization, serving projections
Data Products - EDGAR, Sharadar, GEX, gov/congress data, factors, regimes, etc.
Portfolio / IBOR - investment state, cash, transactions, lots, extracts
PMS - targets, target books, optimizers, rebalance plans, trade intents
Risk - exposures, scenarios, attribution, risk deltas
Reconciliation - broker/custodian comparison, breaks, exceptions
Platform - Dagster/Airflow, Redpanda/Kafka, Vault, observability/Prometheus/Grafana, private-cloud deployment (terraform/ansible, CI/CD)
Access - API, SDK, MCP, Cockpit
and few others. So it is the map of how the platform is actually divided.
We did not start QJ with a candidate-promotion plane. The first version did exactly what the snippet above warns against - it inserted observed symbols straight into the asset master. It worked until a vendor backfill added several thousand foreign and OTC symbols overnight, and suddenly our 'canonical' universe was full of tickers no one had vetted. Untangling that taught us the boundary the hard way: raw evidence and canonical identity are not the same table. The candidate plane exists because we already paid for not having it.
The failure mode is not too many services
It is the distributed monolith - services split physically but tangled logically. You know the signs:
services write into each other’s databases
everyone imports the same shared “domain” library
API, MCP and UI each re-implement the same business logic
shared
utilsquietly holds domain rulesrisk reads whichever holdings table is closest to hand
the warehouse becomes the de facto owner of every dataset
instrument identity is reinvented in three places
one deploy requires five other deploys
events have no schema; contracts have no version
That system carries the full operational cost of microservices and earns none of the independence. The rule that prevents it is one line: split by ownership, not by technology. A repository is not a service. A container is not a boundary. The boundary is the answer to who owns the data, the lifecycle, the contract, the migrations, the writes - and what breaks if this component is wrong.
One concrete boundary: raw evidence is not identity
The cleanest illustration is vendor bulk data. Feeds arrive full of symbols absent from the active universe, and the tempting shortcut is:
if symbol_missing_in_im:
insert_into_assets(symbol)That works in a demo and fails the moment the feed contains foreign listings, OTC aliases, ETF tickers, stale symbols, duplicates and malformed records. Every observed symbol becoming a canonical asset turns your security master into a garbage sink. So we put a discovery-and-promotion plane between the two:
vendor bulk → Warehouse Raw → discovery observations
→ IM candidates → classify → match → enrich
→ controlled promotion → canonical assetThe warehouse keeps the raw evidence; Instrument Master keeps canonical identity clean; candidates sit between them with explicit status - matched_active, matched_inactive_stub, not_in_im, needs_enrichment, ambiguous, excluded, promoted. That layer lets us say exactly which vendor emitted a symbol, which run introduced it, whether it matched, and why its status changed. It is the difference between controlled security-master growth and silently poisoning the universe - and it is the same pattern as every other boundary in the platform.
Point-in-time is infrastructure, not a report option
Buy-side workflows cannot live on “latest.” What did we know when this decision was made? Which portfolio state did this risk run use? Was this fundamental restated afterward? Can we reproduce last month’s report exactly? Answering those requires separating effective time (when something is economically true) from knowledge time (when the system learned it). That distinction has to live in ingestion, storage, materialization and the APIs. Retrofitting it later costs far more than modelling it early - which is why it is a foundation decision, not a feature.
An early version of QJ let a rebalance draft write into the same positions table as live state. For a while it was convenient. Then we could not answer a simple question — was this number what we held, or what we intended to hold? Rebuilding that separation after the fact cost far more than designing it in would have.
Access layers expose truth; they do not own it
APIs, SDKs and MCP are governed windows onto the platform, not a second business layer. Domain services own state, data products own facts, the warehouse owns materialized projections, and the access layer exposes controlled capabilities on top. This matters most for AI: an agent should never guess joins across internal databases. It should call stable tools - resolve instrument, get portfolio state, fetch PIT fundamentals, show unresolved candidates, preview rebalance, explain risk change, read audit evidence. Strong boundaries are what make an agent useful. Without them, AI just produces confusion faster.
The same logic justifies many repositories - smaller context, cleaner ownership, independent CI/CD, lower blast radius, safer parallel work by both humans and coding agents. An agent improving the Cockpit UI has no business touching warehouse migrations.
But repo separation only helps when it mirrors real ownership; otherwise it is ceremony. And the platform repos - infra, edge, vault, bus, orchestration, observability - are not plumbing. On a private-cloud buy-side platform, infrastructure quality is product quality: fragile deploys slow delivery, loose secrets kill credibility, weak observability turns failures into mysteries.
The principle
The principle is not use microservices. It is: Start with the workflow. Then decide what must be owned underneath it.
Import forces identity, state reconstruction and reconciliation. Rebalance forces a clean split between state and intent. Research forces data products and point-in-time data. AI forces governed access. Private cloud forces serious infra. Take the workflows seriously and the architecture stops being arbitrary - it becomes a set of ownership boundaries that hold up as the platform grows.
A CIO sees a workflow. A quant-dev team has to build the machinery underneath it. The hard part was never splitting services. It is splitting the right things - and keeping the contracts strong enough that the whole thing stays coherent under load.
That is QuantJourney. Not microservices for their own sake. A modular buy-side platform built around the boundaries that actually matter.
Why we built QuantJourney this way
Most platforms serving family offices, emerging managers and boutiques fall into one of two camps. The incumbents (Enfusion, Addepar, Bloomberg-class systems) have the domains but carry decades of coupling: changing one thing is slow, the data model is theirs not yours, and “explain this number” routes through a support ticket. The lightweight tools are fast to adopt but collapse exactly the boundaries this post is about - symbol becomes instrument, holdings table becomes state, the warehouse owns everything - so they hit a ceiling the moment a fund needs reproducibility, audit or real risk. We sit in the gap: institutional-grade boundaries, without the institutional-grade inertia.
Three things fall out of that, directly from the architecture:
We define new capabilities fast, without breaking the rest. Because each domain owns its data, lifecycle and contract, a new data product, a new risk view or a new monitored thesis is an additive change inside one boundary - not a migration that ripples across the system. A new dataset becomes a governed product with its own freshness and lineage rules in days, not a quarter. The same separation that keeps numbers correct is what lets us ship quickly: small blast radius is also small lead time.
The platform is genuinely AI-native, not AI-retrofitted. Our MCP and SDK layers expose governed tools over clean domains - resolve instrument, get portfolio state, fetch PIT fundamentals, preview rebalance, explain risk change. An agent reasons over contracts, not over a guessed join across someone’s internal tables. That is only safe because the boundaries underneath are real. Bolt an AI layer onto a distributed monolith and you get confident wrong answers faster; build it on owned domains and the agent becomes a reliable analyst.
Reproducibility and audit are properties of the design, not features we sell separately. Point-in-time semantics, versioned contracts and explicit ownership mean “what did we know then, and can we replay it” is answerable by construction. For an institutional allocator doing diligence, that is the difference between a credible platform and a dashboard.
And it runs in your private cloud, on your infrastructure, with your data never leaving your boundary - because infra is treated as part of the product, not an afterthought. For the funds we serve, that combination - clean domains, fast iteration, AI-native access, reproducible by design, private-cloud - is rare at this size.
That is QuantJourney. Not microservices for their own sake. A modular buy-side platform built around the boundaries that actually matter.
Next in the series: a closer look at IBOR and PMS - how investment state and portfolio-manager intent stay separate, and what that buys you when it is time to explain a number.