

This post is part of a broader effort to make QuantJourney’s architecture more visible. Over the coming weeks, we will explain selected parts of the platform — not as abstract engineering essays, but through the concrete systems we are building: IBOR, PMS workflows, audit, lineage, MCP tools, orchestration, security, and reproducible investment state.
TL;DR
QuantJourney runs as a modular buy-side platform. The investment layer includes IBOR, PMS, Instrument Master, OMS/EMS-facing integrations, reconciliation, rebalancing and optimizer workflows, backtesting, research, and adjacent investment-state services. The platform layer includes warehouse and data lake services, APIs, MCP servers, AI-facing tools, OAuth/RBAC, Dagster orchestration, Kafka/Redpanda messaging, HashiCorp Vault, and audit infrastructure.
That modular architecture gives us strong operational flexibility, but it creates a hard security problem: more than 150 containers across more than 15 private-cloud servers need to call each other without treating network location as proof of identity.
Our answer is deliberately boring: service identities in Vault, OAuth2 client credentials, short-lived RS256 JWTs from
qj-auth, JWKS verification in every receiving service, pinned algorithms, key rotation, runtime access manifests, and one canonical audit pipeline.The point is not clever authentication. The point is operational accountability: when a service affects portfolio state, data lineage, MCP tools, extracts, or audit trails, we need to prove who called what, what they were allowed to do, what changed, and whether the resulting state can be trusted.
Note: QuantJourney is an active platform build. The service-auth foundation described here is already running inside the platform; the next iterations are focused on hardening manifest enforcement, expanding audit coverage, and packaging external POC workflows so these guarantees can be demonstrated end to end.
Once you have more than 150 containers running across more than 15 private-cloud servers, every useful workflow becomes cross-service. A warehouse pipeline registers securities in Instrument Master. Portfolio services read warehouse facts. APIs expose portfolio state. MCP servers let AI agents query and trigger platform capabilities. Audit workers consume events. Dagster orchestrates jobs across domain boundaries.
In other words: services constantly talk to other services.
That same modularity also makes the platform naturally agent-native: AI tools can interact with well-bounded services instead of poking through one large application.
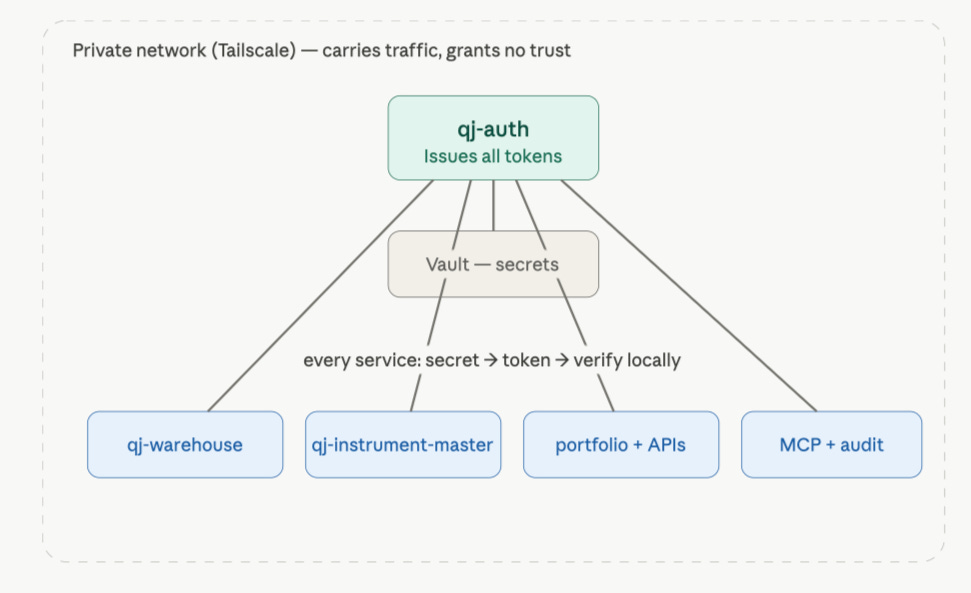
The hard part is making sure they only talk to the services they are allowed to talk to - and that every important call can be reconstructed later.
A private network is not enough: firewall rules, internal DNS, and VM isolation are useful controls, but they do not prove service identity. They tell us where traffic came from. They do not prove who is calling, what workload is behind the request, whether it should be allowed to make that call, or whether we can reconstruct the action later.
That distinction matters in investment infrastructure.
If a service registers instruments, mutates portfolio state, emits an audit event, runs an extract, invokes an MCP tool, or triggers a pipeline, the platform must be able to answer:
Who made the call?
Which service identity did it use?
Was the token valid and unexpired?
Was the caller allowed to do this?
What changed afterward?
Can we prove the sequence later?
This is the problem QuantJourney’s service-to-service authentication is designed to solve.
Not novelty. Not security theater. Not “enterprise architecture” for its own sake.
Operational accountability.
The cast
The example below uses four actors:
qj-warehouse— the data pipeline. It ingests filings, prices, and fundamentals, then writes them where they belong.qj-instrument-master— the system of record for securities. When the warehouse imports a large batch of SEC 13F holdings, this service registers the instruments.qj-auth— the only service allowed to issue short-lived signed service tokens. Nothing else in the fleet can mint one.Vault — the hardened secrets store. It holds long-lived service credentials: not git, not compose files, not application config.
Everything else — portfolio services, APIs, MCP servers, audit workers, Dagster jobs - follows the same pattern. Learn the handshake between the warehouse and Instrument Master, and you understand how the fleet authenticates internal calls.
A monolith has one front door to guard. A service fleet has hundreds of internal doors. Each one needs a lock, and the locks need to be verified the same way.
The handshake
Imagine qj-warehouse-dagster needs to register a large SEC 13F import in the Instrument Master.
It sends a request like:
POST /api/v1/entities/register-bulk
Authorization: Bearer <service-token>The Instrument Master cannot simply trust that the request came from inside the private cloud. Network location is context, not identity. So before business logic runs, the receiving service verifies the caller cryptographically.
The question is not:
Did this request come from our infrastructure?
The question is:
Did
qj-authissue a valid, unexpired token saying this caller issvc.warehouse, intended for QuantJourney services, signed by our current trusted key?
That distinction matters. Network location is context. A signed identity is evidence.
The flow
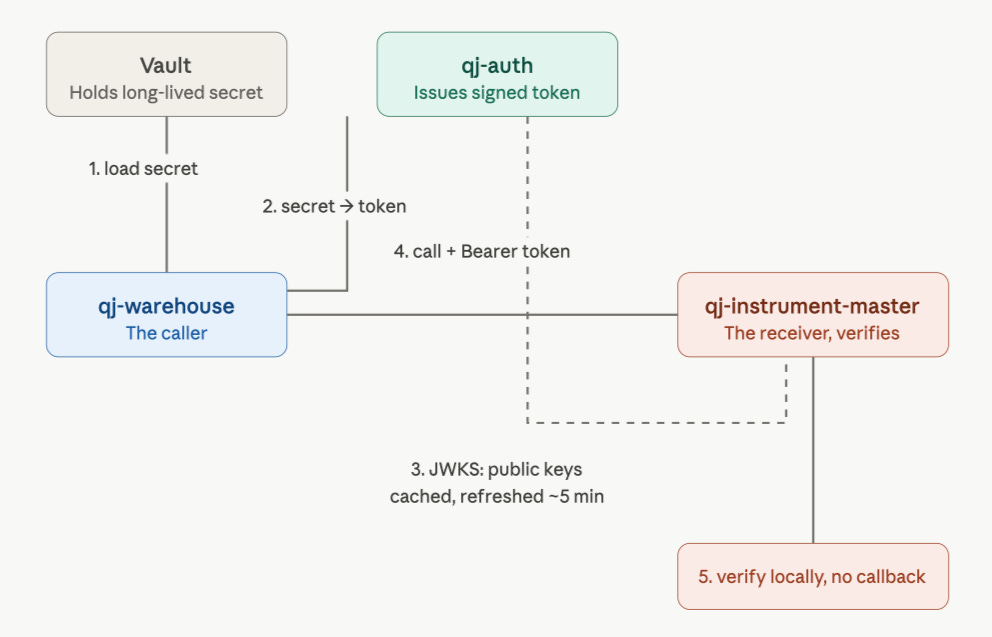
At startup, each service loads its long-lived service credential from Vault. The credential is not stored in git, compose files, or application config.
When a service needs to call another service, it exchanges that credential for a short-lived JWT using the OAuth2 client credentials flow.
qj-auth validates the service identity, builds a token, and signs it with an RSA private key:
{
"sub": "svc.warehouse",
"iss": "<https://auth.quantjourney>",
"aud": "quantjourney",
"iat": 1779556902,
"exp": 1779560502,
"scopes": []
}The caller attaches the token as a bearer token.
The receiving service does not call qj-auth on every request. That would add latency and create an unnecessary dependency on the auth service. Instead, it fetches public signing keys from:
/.well-known/jwks.jsonand caches them locally.
When a request arrives, the receiver:
reads the token header to find the
kid;selects the matching public key from the JWKS cache;
verifies the RSA signature;
checks issuer, audience, expiry, and algorithm;
extracts the service identity from the claims.
If verification fails, the request does not reach business logic.
That gives us a useful property: services can verify identity without making a synchronous call back to the auth service. The auth service issues tokens. The rest of the platform verifies them locally.
This is the difference between centralized identity and centralized runtime dependency.
We want the former. We avoid the latter.
Why RS256 and JWKS
A JWT is just a signed JSON object encoded into a string.
The payload is not encrypted. Anyone holding the token can read the claims. That is fine because we do not put secrets in claims. The token is a signed postcard, not a sealed envelope.
The security property we need is not secrecy of the claims. It is integrity and authenticity:
the payload cannot be modified without breaking the signature;
only
qj-authcan create a valid signature;any service can verify the signature using the public key.
That is why we use asymmetric signing.
qj-auth keeps the private key. Services receive only public keys through JWKS. A verifier can validate tokens but cannot mint them.
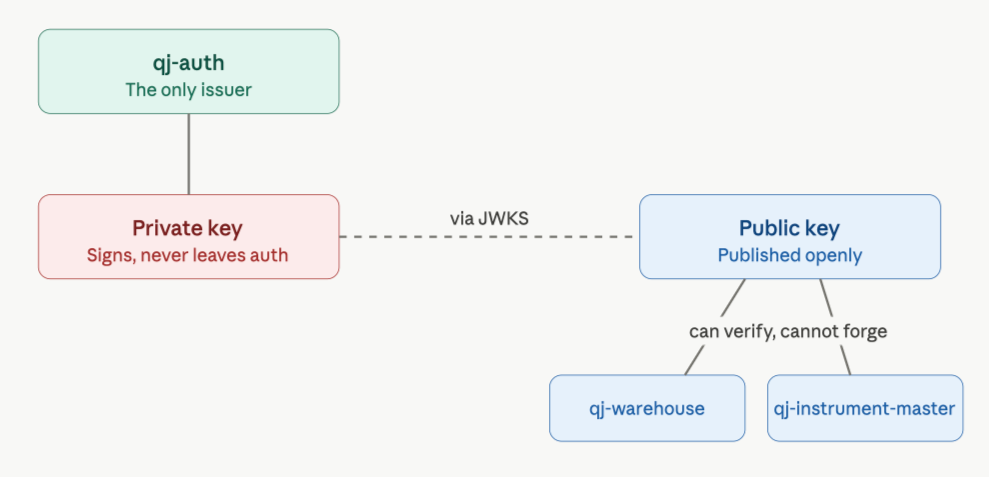
That creates a clean operational boundary: the service that issues identity is not the same as the services that consume identity.
The small detail that matters: algorithm pinning
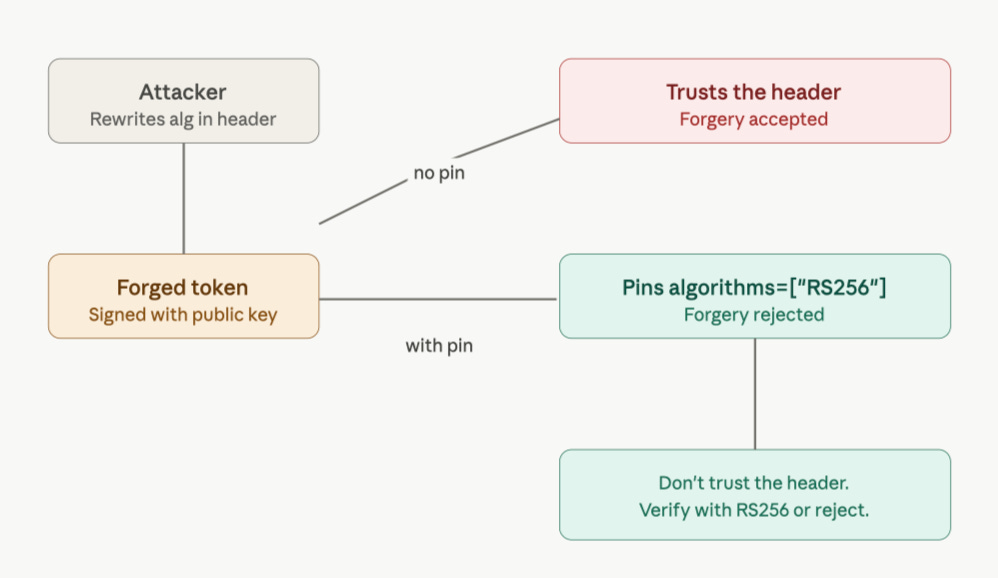
JWT verification has one important footgun: never let the token decide how it should be verified.
The token header contains an alg field. If a verifier blindly trusts that field, it can become vulnerable to algorithm-confusion attacks.
So every service pins the expected algorithm:
jwt.decode(
token,
public_key,
algorithms=["RS256"],
audience="quantjourney",
issuer="<https://auth.quantjourney>",
)This says:
We verify QuantJourney service tokens with RS256. Nothing else.
No none. No unexpected HMAC fallback. No negotiation with attacker-controlled input.
Security often comes down to boring lines like this.
Key rotation without a fleet restart
JWKS also gives us practical key rotation.
The auth service can publish multiple public keys:
the current signing key;
the next key prepared for rotation;
sometimes the previous key while old tokens expire.
When we rotate, qj-auth starts signing new tokens with the new key ID. Services already know how to fetch and cache all published public keys. Old tokens continue to verify until their TTL expires. New tokens verify under the new key.
No coordinated restart across the fleet. No touching every service config. No “we should rotate this someday” operational fantasy.
Rotation has to be easy enough that it actually happens.
Why we did not choose mTLS everywhere
mTLS is strong, and in some systems it is the right answer: ultra-low-latency service calls, Kubernetes-native meshes, or teams already operating internal PKI.
That is not our shape today.
QuantJourney runs a private VM fleet with service-level HTTP APIs, Dagster pipelines, domain databases, MCP servers, and a small engineering surface. For this architecture, JWT + JWKS + Vault gives us the better operating trade-off: cryptographic identity per request, local verification, no service-mesh dependency, clean auditability, and manageable operational load.
What sits above auth: runtime access manifests
The JWT proves who the caller is.
It does not, by itself, prove what the caller should be allowed to touch. That is where our runtime access manifests come in.
Each workload has a generated manifest describing its expected access surface:
identity: svc.qj-warehouse
service: qj-warehouse
workload: qj-warehouse-dagster
api_scopes: [] <intentionally left blank here...>
databases: []
kafka:
consume: []
publish: []
vault:
allowed_paths: []
runtime:
rollout_mode: strict
reason: "Dagster orchestration workload"
generation: 1
generated_at: 2026-05-23T19:21:47Z
valid_until: 2026-05-30T19:21:47Z
hash: sha256:...
inputs:
service_access_hash: sha256:...
service_accounts_hash: sha256:...
topology_hash: sha256:...Visibility without enforcement creates a roadmap. The correct sequence is:
define the access surface;
observe actual behavior;
identify drift;
fix noisy or accidental dependencies;
then enforce.
This is how least privilege becomes operational rather than aspirational. The long-term destination is simple: workloads should not be able to connect to databases, publish Kafka messages, call APIs, or read Vault paths outside their declared manifest. That is the difference between “we have service auth” and “we can reason about service behavior.”
Canonical Vault paths are not glamorous. They matter.
Another deliberately boring decision: standard Vault schemas. Every service stores database credentials under predictable paths with predictable field names.
For example:
secret/qj-<service>/database
secret/qj-<service>/database_admin
secret/qj-<service>/secretsThe value is not that static KV storage is magical. It is not.
The value is operational consistency.
When every service uses the same shape, engineers can reason across the fleet. Deployment scripts can be templated. Auditors get a clean answer. Future migration to dynamic database credentials becomes a systematic change rather than a bespoke migration per service.
This is the kind of platform maturity that does not show up in product screenshots.
But it is exactly what prevents slow entropy.
Audit is part of the auth design
Authentication without audit is incomplete. For QuantJourney, that matters because many service calls are not generic web-app actions. They affect investment infrastructure:
securities are registered;
portfolio state is extracted;
data pipelines are triggered;
MCP tools are invoked by AI agents;
admin operations modify runtime configuration;
reconciliation and reporting workflows depend on reproducible state.
So interesting events flow into a canonical audit pipeline:
service
→ qj_bus.audit.emit_audit(...)
→ Kafka topic: audit.<category>.logged
→ qj-audit-bus consumer
→ TimescaleDB audit table
→ streaming standby on qj-replica
The important part is not the database choice. The important part is convergence.
MCP tool calls, admin operations, system events, auth events, and execution events should not live in five unrelated logging systems with five retention policies.
They should land in one audit model with one query surface and one backup story.
That is what lets us answer questions like:
Which service called this endpoint?
Which identity did it use?
Which workload emitted this event?
Which data changed afterward?
Was the event replicated?
Can we reconstruct the sequence later?
For an investment platform, this is not back-office hygiene - it is part of the product.
Why this matters for buy-side systems
In a normal SaaS product, a bad service call might create a duplicate notification or update the wrong dashboard.
In an investment system, a bad service call can pollute portfolio state, contaminate a backtest, create a false exposure, or make a report unreproducible.
That is why QuantJourney treats service identity as part of investment-state infrastructure.
If a service registers instruments, mutates portfolio events, runs a scenario, emits an AI tool result, or builds an extract, we need to know:
which service did it;
under which identity;
with which declared permissions;
at what time;
from which code path;
producing which audit event;
replicated where;
and whether the result can be reconstructed.
This is the engineering layer underneath point-in-time reproducibility. It is also why we do not want clever auth. We want boring, inspectable, repeatable auth.
The trade-off
Could this be simpler?
We could use shared secrets between services. We could pass static API keys. We could rely on the private network. We could centralize verification by calling auth on every request. We could keep audit as application logs.
All of those choices would be easier in week one.
They become expensive later.
Our current design is not the most sophisticated possible architecture. It is the architecture that gives us the right operating properties:
every service call carries identity;
tokens are short-lived;
verification is local;
signing keys can rotate;
secrets live in Vault;
audit events converge;
workload permissions can move toward enforcement;
the system remains understandable by a small team.
That last point matters. Complex systems do not only fail from missing controls. They fail from controls nobody understands well enough to operate.
Conclusion
The service-auth layer in QuantJourney is intentionally boring.
RS256 JWTs. JWKS. Vault. OAuth2 client credentials. Algorithm pinning. Key rotation. Canonical audit.
None of those primitives are unusual.
What matters is that they are applied consistently across a platform where service calls affect investment state, data lineage, MCP tools, portfolio workflows, and operational audit.
That is the maturity bar we care about: not “can this service call another service?”
but:
can we prove who called what, what they were allowed to do, what changed afterward, and whether the resulting state can be trusted?
For a buy-side platform, that is not infrastructure trivia.
That is the foundation.