
The Hidden Problem in Buy-Side Platforms: Which Investment State Is True?
Dagster, Airflow, and why fund infrastructure needs an asset control plane, not just scheduled jobs.

TL;DR: If you run a fund, you have probably asked these questions before. Did today’s risk run on fresh positions, or yesterday’s? Did this signal use the correct universe? Does the NAV in reporting match the NAV in analytics? When the vendor restated history last quarter, which downstream numbers became invalid? If a code server dies silently on Friday, will you know before Monday’s investment committee?
A green dashboard does not answer any of these questions.
This post is part of the QuantJourney Buy-Side framework series. I am showing not only what the platform does on the screen, but how it is built underneath: data, orchestration, lineage, risk, portfolio state, reporting and operational control. In the last few posts, we covered the Portfolio Management System (PMS). Now we move to the data and process platform. Next, I will also cover Kafka/Redpanda and how an event bus works inside a fund stack.
Building an institutional quant platform has many small traps. Most of them do not look serious at the beginning. One of them is orchestration.
At first it looks like a simple problem: run this Python script at 06:00, run that one after market close, send an alert if something fails. Every quant platform starts accumulating these jobs: ingest this vendor feed, refresh that universe, compute signals, rebuild factors, update risk, generate reports, run checks, archive state. Some run continuously, some once a day, some only after another job completes.
But once the platform becomes real, the question changes. It is no longer “did the job run?” The question is: which investment state did the platform use, and was that state valid at the time?
Most platforms, especially the ones assembled quickly around scripts and dashboards, cannot answer that. They can tell you that a job finished. They can show a green checkmark. They can render a dashboard. But they often cannot tell you whether today’s risk used fresh positions, whether the signal used the correct universe, whether the report used the same NAV series as analytics, or which downstream numbers must be recomputed after a vendor restatement.
That is not a small engineering gap. That is the difference between a platform that runs and a platform that can be trusted.
1. The failure mode that matters
The dangerous failure in a fund stack is not a red job. Red is visible.
The dangerous failure is a green pipeline producing stale or mutated investment state.
Risk runs on yesterday’s positions. Signals run on an old universe. NAV uses the wrong flow treatment. A backtest changes after a vendor restatement. A report renders from data that never passed the right quality gates.
Cron runs commands. Airflow runs task DAGs. Both are useful. But a fund stack needs to track the investment state itself: what produced a number, whether it was fresh, point-in-time correct, checked, and what must be recomputed when history changes.
Dagster starts from that side: assets first, execution second.
2. Why assets, not tasks
The wrong abstraction is: job A runs before job B. That is execution order.
The better abstraction is: asset B depends on asset A. That is investment state.
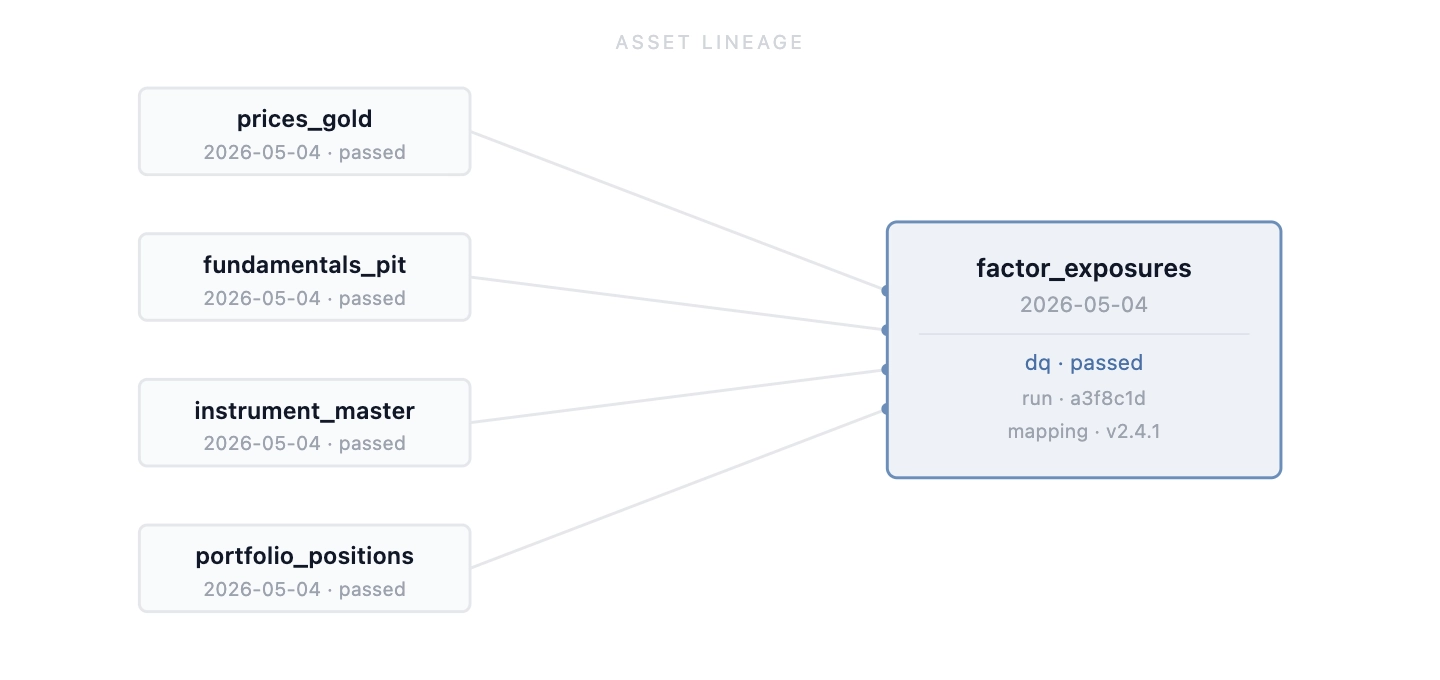
If a factor exposure is wrong, I do not want to reconstruct yesterday’s DAG from logs. I want to inspect the asset:
factor_exposures_daily / 2026-05-04
upstream:
- prices_gold / 2026-05-04
- fundamentals_pit / 2026-05-04
- instrument_master / 2026-05-04
- portfolio_positions / 2026-05-04
materialized_by:
run_id: ...
code_git_sha: ...
mapping_version: ...
dq_status: passedThat is the difference between reconstructing state after the fact and having the state recorded when it was produced.
3. Hub-and-spoke topology
A single Dagster Python process is the wrong shape for QJ.
We use a hub-and-spoke model. The hub runs the webserver, daemon and metadata Postgres. It is the control plane. Spokes are domain-owned Python projects: ingestion, identity, warehouse compute, portfolio, risk, backups, macro. Each spoke owns its dependencies, database access, Vault policy and asset definitions. The hub loads those code locations over private mesh networking.
This keeps domain logic where it belongs. Warehouse owns warehouse assets. Portfolio owns portfolio assets. Risk owns risk assets.
The operational rules are simple: pin Dagster versions across hub and spokes, deploy spokes before hub, bind code servers to private mesh only, and use a queued run coordinator with concurrency caps. These are not elegant rules. They prevent painful incidents.
4. Raw → Validated → Golden
Ingestion should not mean “fetch vendor data and write a table”.
The pattern is:
raw_* → validated_* (canonical) → golden_*Raw is evidence. If a vendor sends bad data, we keep the payload, timestamp, metadata, content hash and run ID. Bad input should be visible and auditable, not silently deleted.
Validated is where normalization and checks happen. Golden is what downstream systems are allowed to consume: risk, signals, reporting and analytics.
A simplified ingestion asset:
@asset(group_name="ingestion")
def vendor_delta_sync(context: AssetExecutionContext) -> Output:
universe = load_universe(context)
if not universe:
return Output(
value={"rows_upserted": 0, "errors": ["empty_universe"]},
metadata={"rows_upserted": MetadataValue.int(0)},
)
total, errors = 0, []
for label, fetch_fn in vendor_fetchers().items():
try:
total += fetch_fn(universe)
except Exception as e:
errors.append(f"{label}: {e}")
return Output(
value={"rows_upserted": total, "errors": errors},
metadata={
"rows_upserted": MetadataValue.int(total),
"errors": MetadataValue.int(len(errors)),
},
)Per-source error isolation does not mean the run is clean. It means one optional slice does not destroy the whole ingestion run. The failed source is recorded, alerting sees it, and DQ decides whether promotion is allowed.
Downstream assets declare dependencies directly in their asset definitions. The dependency is not maintained in a separate DAG file somewhere else; it is part of the asset model.
5. DQ as a promotion gate, not a dashboard
Many systems treat data quality as reporting: a dashboard saying something looks bad. That is not enough.
In a fund stack, DQ should decide whether an asset can be promoted. Raw can exist. Validated can fail. Golden should stay clean.
def create_freshness_check(asset_name, date_column, max_days_old: int = 2):
@asset_check(asset=asset_name, name=f"{asset_name}_freshness_check")
def _check(data: pd.DataFrame) -> AssetCheckResult:
latest = pd.to_datetime(data[date_column]).max()
days_old = (pd.Timestamp.now() - latest).days
return AssetCheckResult(
passed=bool(days_old <= max_days_old),
metadata={"latest_date": str(latest), "days_old": int(days_old)},
)
return _checkIn QJ, checks cover null prices, impossible ranges, stale partitions, missing assets, corporate-action spikes, PIT timestamp violations, broker-vs-IBOR reconciliation and NAV consistency.
The checks are not hard mathematically. What matters is that they are attached to asset materialization. Later we can say not only that prices_gold / 2026-05-04 exists, but that it passed the checks required for downstream risk and reporting.
Rules live in a versioned library, so tightening a rule gives every spoke the same semantics.
6. Restatements are where the architecture is tested
Daily ingestion is not the hard test. Historical mutation is.
Fundamentals restate. Corporate actions arrive late. Split adjustments get corrected. Vendor mappings change. This is normal market-data reality, not an edge case.
If the platform stores only “latest truth”, the past moves under your feet. Backtests change. Screens change. Reports may no longer match the state the PM actually saw at the time.
When a vendor restates history, the question is not: can we run the pipeline again? The real question is: which downstream investment state is invalid now?
fundamentals_pit / 2019Q2
→ valuation_metrics / 2019Q2
→ quality_value_screen / 2019Q2
→ strategy_features / 2019Q2
→ backtest_panel / affected windowWith Dagster this becomes a controlled backfill: select the upstream asset, choose affected partitions, materialize downstream partitions. Without this model, it becomes warehouse surgery: stop cron, write a one-off script, delete rows, rerun jobs, hope nothing else touched the same tables, document it in a Slack thread.
That is not an audit trail. That is improvisation.
7. Portfolio truth has the same problem
NAV, flows, holdings, realized P&L, TWRR, exposure and attribution must agree. If reporting shows one return series, analytics shows another, and backtesting compares against a third, the platform may look polished, but it is not safe.
In QJ we separate three things that must not be conflated.
Actual NAV TWRR is how the real portfolio performed after adjusting for flows. Pro-forma current holdings is what today’s book would have done historically if held backward. Strategy model returns are what the strategy rules would have produced.
All three can be useful. Confusing them is dangerous. Check our previous post on PMS where we explained it all in detail.
Reporting, risk and backtesting must know exactly which portfolio state and return asset they consumed.
8. Two layers of detection
Run-failure sensors catch one class of problem: a run started and failed.
Staleness sensors catch another: a key asset did not materialize recently, or a downstream job is about to consume stale state.
Both are useful, but they do not cover the worst orchestration failure mode: the orchestrator itself failing silently.
A Dagster code server can die. The code location becomes unreachable. Schedules depending on it may not load. No run starts, so no run fails. A run-failure sensor does not fire because there is no failed run to observe.
If the code location responsible for prices, NAV, risk or reporting is dead, the platform can miss an entire production window with no normal failure event.
We added a separate fleet probe.
It is intentionally simple: read the workspace config, check gRPC health for every code server, keep a failure counter, and alert after repeated failures.
def probe_one(host: str, port: int) -> tuple[str, str | None]:
try:
ch = grpc.insecure_channel(f"{host}:{port}")
r = health_pb2_grpc.HealthStub(ch).Check(
health_pb2.HealthCheckRequest(),
timeout=5,
)
return ("SERVING" if r.status == 1 else f"NOT_SERVING_{r.status}", None)
except grpc.RpcError as e:
return ("ERROR", f"{e.code().name}: {str(e.details())[:100]}")9. Backups are also assets
A database backup is not an ops side effect. It is an operational artifact the firm depends on.
The institutional question is not: did cron run pg_dump? The real question is: which production databases have verified, encrypted, restorable backups, and what is the last proven recovery point?
That is an asset question.
In QJ we model backup artifacts as assets: base backups, logical dumps where appropriate, WAL/PITR checkpoints, encrypted uploads, manifests, checksums and restore verification.
A backup asset carries metadata: source database, start and finish time, storage target, encryption status, checksum, size, retention class and verification status.
The abstraction is the same. Something materialized. Something downstream depends on it. It needs lineage, checks, metadata and visibility.
10. What Dagster is not for
Dagster is not a real-time trading engine. Sub-second decisions, tick handling, limit order routing and FIX gateway logic need a different system.
Dagster is not a long-running human workflow engine. “Submit RFQ, wait four hours for approval, route if approved, escalate if not” is a Temporal or Step Functions problem. A Dagster run should not sleep waiting for user approval.
Dagster is not for exploratory research. Researchers should query the warehouse/API, test hypotheses and move quickly. When a research idea becomes a production pipeline, then it becomes an asset.
In QJ, Dagster owns the investment data plane: produce, validate, materialize, partition, observe, backfill, replay. Keep it in that lane and it is strong. Force it into order routing, approvals or notebooks and the failure semantics become wrong.
Fund-grade engineering is also knowing what not to put into a tool.
Summary
The point is not that QuantJourney uses Dagster.
The point is that a buy-side platform needs a control plane for investment state: where a number came from, which data and code versions produced it, whether it passed checks, what depends on it, and what must be recomputed when history changes.
The hard problem is not scheduled Python.
The hard problem is knowing which investment state can be trusted.
— Jakub